Aprendizaje y evolución de estrategias en sistemas multi-agentes
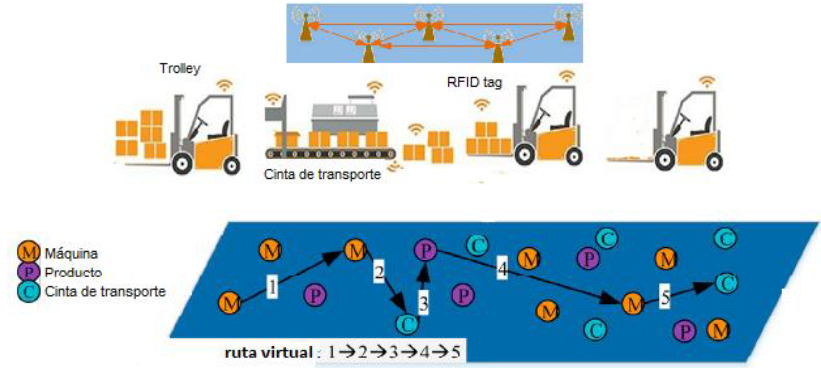 Importancia – Con la inserción de Internet de las Cosas (Internet of Things, IoT) en los ámbitos industriales (IoIT) cada entidad física (i. e., recursos) o virtual (tarea, orden, etc.) tiene una identidad propia, atributos particulares, comportamiento y lógica decisoria individual, sensores/actuadores y puertos de conectividad a otras “cosas” en su entorno de influencia. El piso de planta se transforma así en un sistema multi-agente o “cyber-physical system.” A modo de ejemplo (ver Figura), imaginemos un grupo de carros (“trolleys”) autónomos dedicados a la satisfacción de órdenes compuestas por múltiples ítems (e.g., libros y sus correspondientes tags RFID) en un gran almacén. Existen diferentes órdenes a ser satisfechas y los carros deben optimizar simultáneamente sus acciones de navegación y aprovisionamiento a través de una plataforma IoT. Así cada carro, es un agente situado que puede tomar distintas acciones, y desconociendo las estrategias de los otros carros, debe aprender a elegir las acciones que maximizan alguna métrica de beneficio, por ejemplo, minimizar el número de movimientos para completar una orden. Las interacciones entre los agentes generan una evolución permanente de la estrategia de cada uno de ellos dependiendo del número de órdenes y los inventarios de cada producto.
Importancia – Con la inserción de Internet de las Cosas (Internet of Things, IoT) en los ámbitos industriales (IoIT) cada entidad física (i. e., recursos) o virtual (tarea, orden, etc.) tiene una identidad propia, atributos particulares, comportamiento y lógica decisoria individual, sensores/actuadores y puertos de conectividad a otras “cosas” en su entorno de influencia. El piso de planta se transforma así en un sistema multi-agente o “cyber-physical system.” A modo de ejemplo (ver Figura), imaginemos un grupo de carros (“trolleys”) autónomos dedicados a la satisfacción de órdenes compuestas por múltiples ítems (e.g., libros y sus correspondientes tags RFID) en un gran almacén. Existen diferentes órdenes a ser satisfechas y los carros deben optimizar simultáneamente sus acciones de navegación y aprovisionamiento a través de una plataforma IoT. Así cada carro, es un agente situado que puede tomar distintas acciones, y desconociendo las estrategias de los otros carros, debe aprender a elegir las acciones que maximizan alguna métrica de beneficio, por ejemplo, minimizar el número de movimientos para completar una orden. Las interacciones entre los agentes generan una evolución permanente de la estrategia de cada uno de ellos dependiendo del número de órdenes y los inventarios de cada producto.
Problemática – La autonomía para actuar que disponen las “cosas” o agentes en IoT es la clave para lograr mayores niveles de productividad y eficacia. Sin embargo, tal autonomía requiere que la optimización conjunta en tiempo real de todas las acciones sea un emergente de las estrategias que de manera selfish cada agente utiliza. El aprendizaje individual de cada agente está mayormente basado en los beneficios/costos inmediatos de las acciones que elige y aplica. La percepción del estado del resto (otros agentes y objetos) es bastante limitada o inexistente. En el mejor de los casos, un agente puede conocer a posteriori las acciones tomadas por los otros agentes, pero en ningún caso puede conocer su estrategia o estado interno. El empleo de reglas de aprendizaje desacopladas y la multiplicidad de escenarios donde ocurren las interacciones con otros agentes son las únicas fuentes para la adaptación y evolución de la estrategia de cada agente.
Objetivos – Desarrollo de algoritmos para aprendizaje por ensayo (probe) y ajuste (adapt) que promuevan la optimización distribuida de las acciones de los distintos agentes sin un control centralizado. Las reglas de aprendizaje diseñadas serán evaluadas usando simulación basada en agentes implementando casos de estudio en lenguajes como Netlogo y Anylogic. El enfoque metodológico se centrará en una perspectiva de teoría de juegos no cooperativos para garantizar la convergencia hacia condiciones cercanas al equilibrio de Nash, El análisis de los algoritmos buscará identificar las condiciones necesarias para maximizar una función de bienestar (wellfare) del sistema multi-agente en su conjunto. También se estudiará la evolución de las estrategias desde la perspectiva de los juegos de coaliciones.
Contacto: Dr. Ernesto C. Martínez (ra.vo1743648107g.tec1743648107inoc-1743648107efatn1743648107as@ra1743648107gnIsa1743648107ceb1743648107)